Dataset
The official dataset of the challenge
The training set can be downloaded here, using the password which will be provided to all registered teams: ICASSP-2023-eeg-decoding-challenge-dataset
For more details concerning the dataset, we refer to the dataset paper.
EEG
Electroencephalography (EEG) is a non-invasive method to record electrical activity in the brain, which is generated by ionic currents that flow within and across neuron cells. When a large population of thousands or millions of neurons with a similar orientation in a specific brain region synchronises its electrical activity, the produced electrical field is large enough to be observable on the scalp. When we attach an array of electrodes on the scalp, these electrical fields can be recorded by measuring the electrical potential (typically 10 − 100μV) between pairs of electrodes in the array.
Data Collection
We measure EEG data in a well-controlled lab environment (soundproof and electromagnetically shielded booth), using a high-quality 64- channel Biosemi ActiveTwo EEG recording system with 64 active Ag-AgCl electrodes and two extra electrodes, which serve as the common electrode (CMS) and current return path (DRL). The data is measured at a sampling rate of 8192 Hz. While the temporal resolution is high, the spatial resolution is low, with only 64 electrodes for billions of neurons. All 64 electrodes are placed according to international 10-20 standards.
The dataset contains data from 85 young, normal-hearing subjects (all hearing thresholds <= 25 dB Hl), with Dutch as their native language. Subjects indicating any neurological or hearing-related medical history were excluded from the study. The study was approved by the Medical Ethics Committee UZ KU Leuven/Research (KU Leuven, Belgium). All identifiable subject information has been removed from the dataset.
Each subject listened to between 8 and 10 trials, each of approximately 15 minutes in length. The order of the trials is randomized between participants. All the stimuli are single-speaker stories spoken in Flemish (Belgian Dutch) by a native Flemish speaker. We vary the stimuli between subjects to have a wide range of unique speech material. The stimuli are either podcast or audiobooks. Some audiobooks are longer than 15 minutes. In this case, they are split into two trials presented consecutively to the subject.
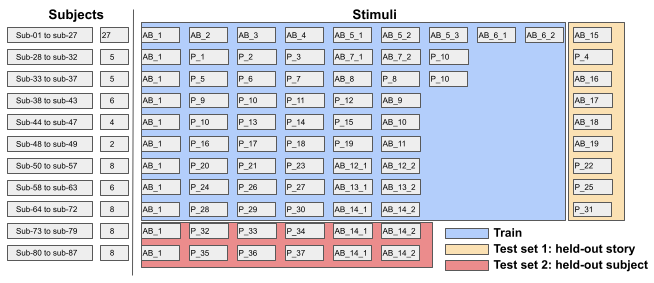
Division into train and test set
Training set
The training set contains EEG responses from 71 subjects. These subjects are numbered from sub-01 to sub-071. As shown in the figure above, each subject listens to between 6 and 9 trials, each of around 15 minutes in length. Due to measuring errors, not all trials for all subjects have been included in the training set. Subjects are divided into groups, depending on which stimuli they listened to. Each such group contains between 2 and 27 subjects. All subjects of all groups listen to a reference story, Audiobook 1.
In total, the training set contains 508 trials, from 71 subjects, using 57 different stimuli. The total amount of minutes of data amounts to 7216 minutes (120 hours). Both tasks share the training set. Data is structured in a folder per subject, and the trials are named chronologically. Each EEG trial file contains a pointer to the stimulus used to generate the specific brain EEG response and reference to the subject identifier. The auditory stimuli are provided in a separate folder stimuli.
Test set
The test set consists of two parts: held-out stories and held-out subjects. These sets are split into two parts, ensuring that the test sets of the two tasks do not overlap. Both test sets will be released to the participants on January 6, 2023. However, the ground truth labels will only be available to the public after the competition is over.
- Test Set 1 (held-out stories) contains data for the 71 subjects seen in training. We held out one story for each group of subjects, which never occurs in the training set, amounting to a total of 944 minutes.
- Test Set 2 (held-out subjects) contains data for 14 subjects (sub-72 to sub-85) that are not in the training set, further referred to as held-out subjects, for a total of 1260 minutes. The data for these subjects were acquired using the same protocol as for the other 71 subjects.
Preprocessing
We provide two versions of the dataset. The first data version is the raw EEG data, which has been downsampled from 8192 Hz to 1024 Hz. The second version of the dataset has been preprocessed in MATLAB. First, the EEG signal was downsampled from 8192 Hz to 1024 Hz, and artefacts were removed using a multichannel Wiener filter. Then, the EEG signal was re-referenced to a common average. Finally, the EEG signal was downsampled to 64 Hz. These steps are commonly used in EEG signal processing, and the preprocessed version can be used directly in machine learning models. However, challenge participants are free to perform their own preprocessing on both versions of the datasets. For the regression task, we define a specific version of the envelope, which will be used for evaluating the final outputs. We estimate the envelope using a gammatone filter bank with 28 subbands, spaced by equivalent bandwidth with center frequencies of 50 Hz to 5 kHz. Subsequently, the absolute value of each sample in the filters is taken, followed by exponentiation with 0.6. Then, all subbands are averaged to obtain one speech envelope. Finally, the resulting envelope is downsampled to 64 Hz. We provide code to create these envelope representations.
Ethics
Before commencing the EEG experiments, all participants read and signed an informed consent form approved by the Medical Ethics Committee UZ KU Leuven/Research (KU Leuven, Belgium). All participants in this dataset gave explicit consent for their pseudoanonymized data to be shared in a publicly accescible dataset. All identifiable subject information has been removed from the dataset.